Today’s Agenda
- Aggregation+Group by
- string/Date/Time Operation
- Output control+Redirection
- Window Functions
- Nested Queries
- Lateral Joins
- Common Table Expressions
我们的任务是从理论上理解这些概念,并且对它们的实际应用场景有所认识。
NOW的侧写
我粗糙地看了一遍课程视频,讲师利用终端演示不同DBMS对查询语句的使用。但是背后的原理是相同的。因此我应该着重理解这些语句的原理以及其实现各种目的的应用,而不是记忆不同DBMS的特殊规范。在CMU 15445#01对于基本的语句,比如投影、选择、连接等,我有所了解,对于这些进阶的概念,我希望用这些概念搭建起上面复杂的概念。
Aggregation + Group by
聚合函数
aggregates:Functions that return a single value from a bag of tuples.
Aggregation (聚合函数)的核心是 “塌缩” (Collapse) 或者叫 “汇总” (Summarize)。它把一“袋” (bag) 的元组(多行数据)作为输入,然后“挤压”成一个单一的值。
这个流程是这样的:
- 准备数据源 (Bag of Tuples):
- 这个数据源可以是一整张表,比如
students。 - 也可以是经过关系代数运算后的结果。比如,
SELECT * FROM students WHERE major = 'CS',这个查询的结果(所有CS专业的学生)就是聚合函数的输入数据源。
- 这个数据源可以是一整张表,比如
- 提取目标列:
- 当你说
AVG(score)时,聚合函数会从输入的数据源(那一袋子元组)中,把每一行的score列的值都抽出来,形成一个值的列表(a list of values)。
- 当你说
- 执行计算:
AVG: 对这个值的列表求平均值。SUM: 对这个值的列表求和。MIN/MAX: 找出这个列表中的最小/最大值。COUNT: 计算这个列表里有多少个值。
- 输出单一值:
- 最后,整个过程只返回一个数字。
特别的对于COUNT,我们有三种不同的用法:COUNT(col),COUNT(*),COUNT(DISTINCT col)
对于COUNT(col):计算所有非NULL元组的个数
对于COUNT(*):计算所有行(不管是否为NULL)的个数
对于COUNT(DISTINCT col):计算所有非重复元组个数
聚合函数的位置
Aggregate functions can (almost) only be used in the SELECT output list
SQL查询具有 逻辑执行顺序 (Logical Processing Order),其顺序通常是:
FROM: 确定要操作的表。WHERE: 过滤行。对FROM得到的每一行,应用WHERE子句的条件,只保留满足条件的行。这一步是逐行操作的。GROUP BY: (如果存在) 将经过WHERE过滤后的行进行分组。HAVING: (如果存在) 过滤分组。对GROUP BY之后产生的每个组,应用HAVING的条件。SELECT: 计算最终要输出的列。ORDER BY: 对最终结果进行排序。LIMIT: 限制输出的行数。
聚合函数(如 COUNT, AVG)的本质是对 一组行 (a group of rows) 进行计算。它在上面的很多地方是违法的。比如WHERE,它是对每一行都进行判断过滤,如果在这里用聚合函数,看不到全局。
-- 错误示范: WHERE子句无法知道全局的COUNT是多少
SELECT student_id, login
FROM student
WHERE COUNT(*) > 10; -- 这是没有意义的,判断每一行时,COUNT(*)是多少?SELECT 子句在逻辑上的执行顺序很靠后(第5步)。到这一步时,数据库已经完成了 FROM, WHERE, GROUP BY 这些步骤。它已经有了一个明确的、准备用来计算最终结果的 行的集合(如果用了 GROUP BY,就是多个行的集合)。在这个阶段,对这个(或这些)行的集合进行聚合计算是完全可行的。
这个 “almost” 指的是,聚合函数还有一个地方可以用:HAVING 子句。HAVING 子句专门用来对 GROUP BY 之后的分组结果进行过滤。因为此时分组已经形成,对每个分组进行聚合计算并判断是完全合理的。
SELECT class_id, COUNT(*)
FROM student_enrollment
GROUP BY class_id
HAVING COUNT(*) > 30; -- 在这里使用聚合函数是合法的教师在这里还用了COUNT的不同表达,在这里结果相同,我还是强调一下细节差异。
SELECT COUNT(login) AS cntSELECT COUNT(*) AS cntSELECT COUNT(1) AS cnt
主要是如何理解这里的“1”,它并不是数据库中的某一列或者别的什么有价值的东西。这需要我们进一步拆解COUNT的执行过程:
- 数据库首先通过
FROM和WHERE子句,确定了一个需要处理的 中间结果集(比如,所有login以@cs结尾的学生,我们还是假设有100行)。 - 现在,
COUNT(expression)开始对这个结果集的 每一行 逐一进行操作。 - 对于 每一行,它都会计算括号里的
expression(表达式) 的值。- 如果
expression是一个列名,比如login,它就获取这一行login列的值。 - 如果
expression是一个常量,比如1,那么对于 每一行,这个表达式的结果 永远是1。 - 如果
expression是*,它是一个特殊符号,意思是“这一行本身”。
- 如果
- 计算出表达式的值之后,
COUNT函数进行判断:- 这个值是
NULL吗?- 如果是
NULL,忽略,计数器不增加。 - 如果 不是
NULL,计数器加一。
- 如果是
- 这个值是
- 遍历完所有行后,返回计数器的最终值。
所以,COUNT(1) 的本质是:为结果集中的每一行提供一个永不为NULL的“占位符”,然后计算有多少个这样的占位符。这样看来COUNT(1),COUNT(2)什么的都没有区别哦(只要不是COUNT(NULL)就行)
GROUP BY的必要性
一个典型的错误:
SELECT AVG(s.gpa), e_cid
FROM enrollment AS e JOIN students AS s
ON e_sid = s_sid数据库被要求做两件相互矛盾的事情:
AVG(s.gpa): 请把所有行的gpa压缩成 一个 平均值(结果是3.86)。e.cid: 请把 每一行 的cid都给我。
正确的做法是运用GROUP BY:
SELECT
AVG(s.gpa), -- 这个 AVG 现在是计算每个组内的平均值
e.cid -- 这个 e.cid 就是当前这个组的 cid (因为组内所有行的 cid 都一样)
FROM
enrolled AS e
JOIN
student AS s ON e.sid = s.sid
GROUP BY
e.cid; -- 按课程ID进行分组注释:演示的时候,有些数据库会从这个聚合函数聚合的bag中随便挑一个给你,造成混乱。大多数数据库会报错。
“Non-aggregated values in SELECT output clause must appear in GROUP BY clause.”
(在 SELECT 输出子句中,没有被聚合的(普通)值,必须出现在 GROUP BY 子句中。)
SELECT
AVG(s.gpa), -- 聚合列
e.cid, -- 非聚合列 (普通列)
s.name -- 非聚合列 (普通列), 被红框标出
FROM
enrolled AS e, student AS s
WHERE
e.sid = s.sid
GROUP BY
e.cid; -- 只按课程ID分组这是错误的,因为s.name是非聚合列,但是他没有出现在GROUP BY中。
HAVING:对于GROUP BY的筛选
HAVING之于GROUP BY作用类似于WHERE
因为HAVING的筛选面向一组数据行,所以可以用聚合函数
SELECT AVG(s.gpa) AS gpa_avg , e.cid
FROM enrollment as e, students as s
WHERE e.cid = s.cid
GROUP BY e.cid
HAVING AVG(s.gpa>3.9)
STRING OPERATIONS
不同数据库大小写敏感性和引号的区分
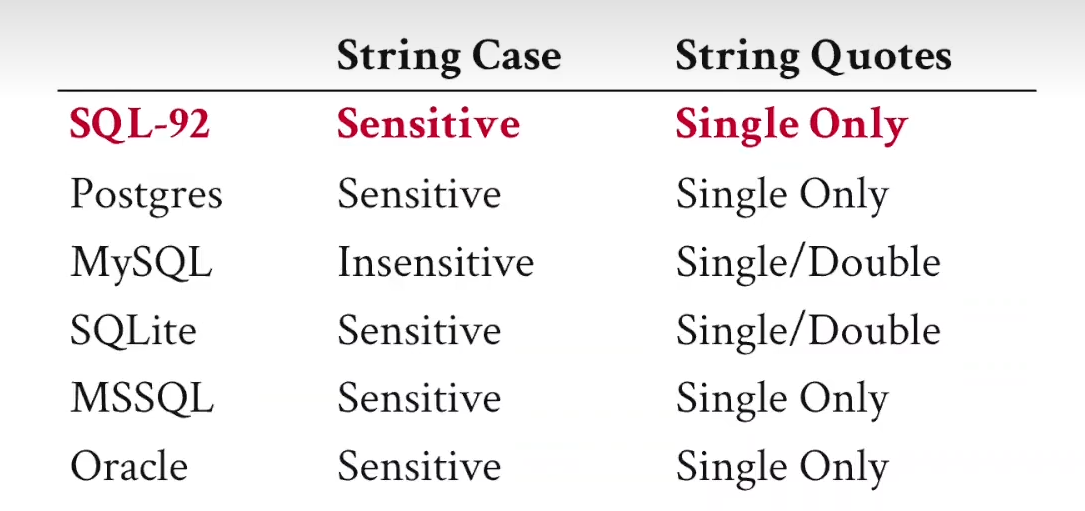
这张表格对比了不同数据库系统(DBMS)在处理字符串时的两个关键特性:
1. String Case (大小写敏感性)
Sensitive(大小写敏感): 这意味着在进行字符串比较时,数据库会认为'Andy'和'andy'是 不同 的字符串。这是 SQL-92 标准的规定,也是大多数数据库(如 Postgres, SQL Server, Oracle)的默认行为。Insensitive(大小写不敏感): 这意味着数据库在比较时会忽略大小写,认为'Andy'和'andy'是 相同 的。MySQL 是这里最著名的例子。
2. String Quotes (字符串引号)
Single Only(只用单引号): 这是 SQL-92 标准。标准规定,字符串字面量(string literals)必须用单引号 (') 括起来。例如,'hello world'。双引号 (") 在标准SQL中是用来包裹标识符(如表名或列名)的,特别是当它们包含特殊字符或与关键字冲突时,例如SELECT "my column" FROM "my table"。Single/Double(单双引号通用): 一些数据库,如 MySQL 和 SQLite,为了方便使用,放宽了这个限制,允许你使用单引号或双引号来定义字符串。
LIKE和两个通配符
LIKE 用在 WHERE 子句中,其语法结构是:column_name LIKE 'pattern'
它的意思是:“检查 column_name 列中的值,看它是否符合 'pattern' 所描述的模式”。
这个模式是由普通字符和特殊的“通配符”组合而成的。
课堂上介绍的两个通配符如下:
% (百分号): 匹配任意数量的任意字符 (包括零个)
_ (下划线): 匹配有且仅有一个任意字符
课程中提出了两个示例:
示例一: WHERE e.cid LIKE '15-%'
- 目标: 查找所有以
'15-'开头的课程ID (cid)。 - 模式分析:
'15-%''15-': 这部分是普通字符,表示字符串必须以'15-'精确开头。%: 这部分是通配符,表示在'15-'后面,可以有 任意数量的任意字符。
- 可能匹配到的值:
'15-445'(匹配)'15-213'(匹配)'15-721'(匹配)'15-'(也匹配,因为%可以匹配零个字符的空字符串)
- 不会匹配的值:
'70-200'(开头不是'15-')'015-445'(开头不是'15-')
示例二: WHERE s.login LIKE '%@c_'
- 目标: 查找所有以
@c开头,并且@c后面 刚好还有一位字符 的登录名 (login)。 - 模式分析:
'%@c_'%: 表示在'@c'前面,可以有任意数量的任意字符。这允许我们匹配任何以@c_结尾的字符串。'@c': 普通字符,表示必须包含子串'@c'。_: 通配符,表示在'@c'后面,必须有且仅有一个字符。
- 可能匹配到的值:
'andy@cs'(匹配:%匹配'andy',_匹配's')'pavlo@cn'(匹配:%匹配'pavlo',_匹配'n')'@c1'(匹配:%匹配空字符串,_匹配'1')
- 不会匹配的值:
'user@cmu'(@c后面有两位字符'mu')'root@c'(@c后面没有字符了)'student@gmail.com'(不包含'@c_'模式)
字符串拼接 (String Concatenation)
字符串拼接就是把两个或多个字符串“粘”在一起,形成一个更长的字符串。应用场景有:动态生成文本、组合姓名、构建URL等。
课程通过一个统一的目标来展示三种不同的实现方法。这个目标是:找到那些 login 等于其小写 name 加上 '@cs' 后缀的学生。
示例一:SQL-92 标准 (||)
SELECT name FROM student
WHERE login = LOWER(name) || '@cs'|| (双竖线): 这是 SQL-92标准 中定义的字符串拼接操作符。它在逻辑上最清晰,就像数学中的 + 号一样,表示将左右两边的字符串连接起来。支持的数据库包括 PostgreSQL, Oracle, 和 SQLite。
示例二:MSSQL (Microsoft SQL Server) (+)
SELECT name FROM student
WHERE login = LOWER(name) + '@cs'+ (加号): 在 Microsoft SQL Server (以及 Sybase) 中,+ 号被重载 (overloaded) 了。当 + 的两边都是字符串类型时,它执行的是字符串拼接操作,而不是数学加法。
这种写法在其他大多数数据库中是 错误的。
示例三:MySQL (CONCAT 函数)
SELECT name FROM student
WHERE login = CONCAT(LOWER(name), '@cs')CONCAT()函数: MySQL 选择了提供一个专门的函数CONCAT()来执行字符串拼接。你需要将所有想拼接的字符串作为参数传递给这个函数。CONCAT(str1, str2, ...): 这个函数可以接受两个或更多的参数,并将它们按顺序拼接在一起。
在 MySQL 中,|| 是逻辑 “或” (OR) 操作符的同义词。所以 A || B 等价于 A OR B。这是 MySQL 一个非常独特的、不符合SQL标准的行为。(注:在开启特定SQL模式后,MySQL也可以将 || 解释为拼接)
DATE/TIME OPERATION
Operations to manipulate and modify DATE/TIME attributes.
Can be used in both output and predicates.(即SELECT和WHERE)
Support/syntax varies wildly...
REDIRECTION
store query result in another table
two conditions must be followed:
–>the table must NOT be already defined
–>new table will have same # of the columns with the same types as the input
OUTPUT CONTROL
FETCH 和 OFFSET
FETCH {FIRST | NEXT} <count> ROWS ONLY
OFFSET <count> ROWSETCH {FIRST | NEXT} <count> ROWS ONLY:
- 作用: 这部分用来限制你 获取 (fetch) 的行数。
{FIRST | NEXT}: 这两个关键字在功能上是等价的,可以互换使用,只是语义上稍有不同。FIRST(前)和NEXT(接下来)都可以理解为“接下来的N行”。<count>: 你想获取的行数,比如10。ROWS ONLY: 这是语法的标准结尾,有些数据库也支持ROW(单数)。- 简单来说:
FETCH FIRST 10 ROWS ONLY就等同于“只取10行”。
OFFSET <count> ROWS
OFFSET <count> ROWS:- 作用: 这部分用来 跳过 (skip) 开头的若干行。Offset就是偏移量的意思。
<count>: 你想跳过的行数。- 简单来说:
OFFSET 20 ROWS就是“跳过前20行,从第21行开始”。
用处是可以实现限制输出的显示数量和实现分页效果。
有关分页效果具体如下:
组合使用 OFFSET 和 FETCH ,以新闻网站的分页为例
想象一个新闻网站的列表,每页显示10篇文章。
- 第1页:
OFFSET 0 ROWS FETCH FIRST 10 ROWS ONLY(跳过0行,取10行) - 第2页:
OFFSET 10 ROWS FETCH FIRST 10 ROWS ONLY(跳过前10行,再取10行) - 第3页:
OFFSET 20 ROWS FETCH FIRST 10 ROWS ONLY(跳过前20行,再取10行)
通过改变 OFFSET 的值,可以获取任何位置的切片。
WINDOW FUNCTIONS
Performs a calculation across a set of tuples that are related to the current tuple, without collapsing them into a single output tuple.
在一组与当前行相关的元组上执行计算,但不会将它们压缩成单个输出元组.
窗口函数 保留了原始的行数。输入是100行,经过窗口函数的计算,输出还是100行。它只是为这100行中的每一行都新增了一个计算结果列。
to support running totals, ranks, and moving averages.
以支持 累计总和、排名 和 移动平均值。
核心语法如下:
SELECT FUNC-NAME(...) OVER (...)
FROM tableName其中:
FUNC-NAME(...): 这部分是窗口函数本身。它可以是:
- 专用的窗口函数: 如
RANK(),LAG(),LEAD()。 - 普通的聚合函数: 如
SUM(),AVG(),COUNT()。当这些聚合函数后面跟了OVER子句时,它们就变成了窗口函数,行为也随之改变(不再压缩行)
OVER (...)这是窗口函数的核心,被称为“窗口子句”。括号里的内容定义了“窗口”的范围和行为。它通常包含三个部分(都是可选的):
PARTITION BY ...: 分组。它告诉函数窗口的边界在哪里。类似于GROUP BY,它会把数据按PARTITION BY的列分成不同的“分区”(Partition)。所有的计算都在各自的分区内独立进行。例如PARTITION BY department_id表示按部门分区。ORDER BY ...: 排序。它定义了分区内部各行的顺序。对于排名、累计总和、移动平均这类跟顺序相关的计算,ORDER BY是必需的。ROWS/RANGE BETWEEN ...: 定义窗口帧 (Window Frame)。这是更精细的控制,定义了在分区内部,对于当前行,它的计算范围具体是哪些行(比如“往前3行到往后3行”)。
NESTED QUERY
Nested Queries (嵌套查询),也常被称为 Subqueries (子查询).顾名思义,就是一个查询嵌套另一个查询。
课程通过两个个例子展示了子查询可以出现的主要位置:WHERE, SELECT 子句中。实际上,它最常出现的另一个位置是 FROM 子句。
示例一:子查询在 WHERE 子句中 (最常见的用法)
SELECT name FROM student
WHERE sid IN (SELECT sid FROM enrolled);- 外部查询 (Outer Query):
SELECT name FROM student WHERE sid IN (...) - 内部查询 (Inner Query):
SELECT sid FROM enrolled - 目标: 查找所有 至少选了一门课 的学生的姓名。
- 执行逻辑:
- 先执行内部查询:
SELECT sid FROM enrolled。这个查询会返回一个包含所有选过课的学生ID的 列表 (list),比如(101, 102, 103, 101, ...)。数据库会对这个列表进行去重,得到一个唯一的ID集合。 - 再执行外部查询: 外部查询现在变成了
SELECT name FROM student WHERE sid IN (唯一的学生ID集合)。它会遍历student表,检查每个学生的sid是否存在于内部查询返回的集合中。如果存在,就选出这个学生的name。
- 先执行内部查询:
- 子查询返回类型: 在
IN操作符中,子查询必须返回 单一一列 的结果。
示例二:子查询在 SELECT 列表中 (相关子查询)
SELECT sid,
(SELECT name FROM student AS s WHERE s.sid = e.sid) AS name
FROM enrolled AS e;- 外部查询:
SELECT sid, (...) AS name FROM enrolled AS e - 内部查询:
(SELECT name FROM student AS s WHERE s.sid = e.sid) - 目标: 对于
enrolled表中的每一条选课记录,都找出对应的学生姓名。 - 执行逻辑 (非常重要!):
- 这是一个 相关子查询 (Correlated Subquery)。它的内部查询依赖于外部查询的值 (
e.sid)。 - 数据库处理
enrolled表的 每一行 (e)。 - 对于
enrolled的 第一行,假设e.sid是101,数据库会执行内部查询SELECT name FROM student WHERE sid = 101,得到'Alice'。然后外部查询的第一行结果就是(101, 'Alice')。 - 对于
enrolled的 第二行,假设e.sid是102,数据库会再次执行内部查询SELECT name FROM student WHERE sid = 102,得到'Bob'。然后外部查询的第二行结果就是(102, 'Bob')。 - … 以此类推,直到处理完
enrolled表的所有行。
- 这是一个 相关子查询 (Correlated Subquery)。它的内部查询依赖于外部查询的值 (
- 子查询返回类型: 在
SELECT列表中,子查询必须是 标量子查询 (Scalar Subquery),即它必须保证只返回 单一一列 和 单一一行 的结果。在这个例子中,因为sid是主键,所以WHERE s.sid = e.sid保证了只返回一行。 - 性能: 相关子查询通常性能较差,因为内部查询需要为外部查询的每一行都执行一次。能用
JOIN解决的问题,尽量用JOIN。- 等价的
JOIN写法:SELECT e.sid, s.name FROM enrolled e JOIN student s ON e.sid = s.sid;
- 等价的
补充示例:子查询在FROM中
SELECT dept_name, avg_salary
FROM (
SELECT dept_name, AVG(salary) as avg_salary
FROM employee
GROUP BY dept_name
) AS dept_salaries
WHERE avg_salary > 50000;- 内部查询:
(SELECT dept_name, AVG(salary) ...) - 作用: 内部查询的结果被当作一个 临时的、虚拟的表(称为派生表,Derived Table),并被赋予了别名
dept_salaries。 - 外部查询: 外部查询就可以像查询一张普通的表一样,来查询这个临时的
dept_salaries表。 - 优势: 这种用法非常普遍,它可以让你先对数据进行聚合、转换,然后再对这个中间结果进行进一步的查询和过滤。这比在
HAVING中写复杂逻辑通常更清晰。
NEW的侧写
说实话,笔者对于后几种语句的理解还并不到位。比如说nested query和之前的window function,在我看来,它们之间的很多部分都是可以相互替代的。很多用法甚至用基本的join都可以实现。他们基本上相当于同一要求的不同写法。我知道在原有概念的基础上定义新的概念通常是用于简化我们对于复杂问题的流程,但是目前我根本看不出这些定义的独一无二之处。(或许是我还没有接触到具体的作业)
光是看着他们的语法就让我头痛了,我希望在part 2之前精进这一切。但是今天是星期天,我需要交差,所以不得不发布这一切。